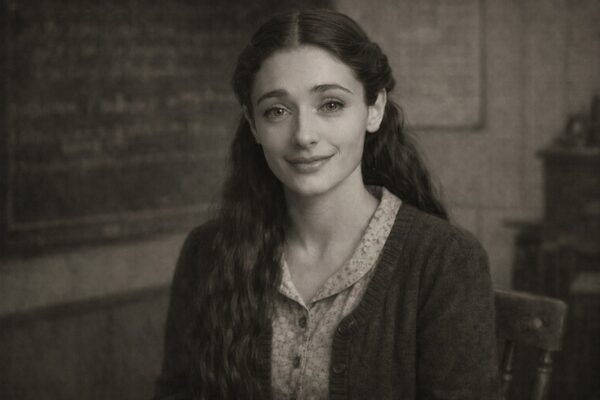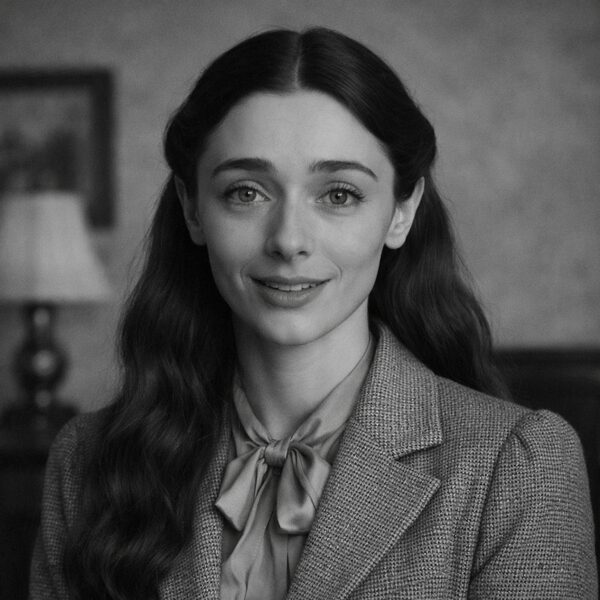Proof of Antiquity for AI voices — dead accents preserved on vintage hardware compute.
The first open-source TTS model for historical speech patterns. Fine-tuning F5-TTS on 164 hours of public domain vintage audio (1888–1955) to preserve extinct and endangered accents.
Modern TTS models sound modern. No AI can speak with a transatlantic accent, a 1940s newsreel cadence, or the speech patterns of someone born before the Civil War. These voices are disappearing from living memory.
Additionally, Cajun French — a UNESCO “severely endangered” language — has approximately 150,000 speakers remaining, mostly elderly. When this generation passes, the language dies with them.
Demo
Early prototype — Sophia Elya speaking in transatlantic accent (SadTalker + F5-TTS)
Voice Presets
Each preset trains on a specific era and accent. Sophia Elya appears in period-accurate imagery for each voice.
Edison
1890s · Wax cylinder
Cajun French
1880s · Attakapas prairie
Cajun French
1920s · Cloche hat
Cajun English
1930s · Schoolteacher
Fireside
1940s · By the hearth
Transatlantic
1940s · Tweed blazer
Newsreel
1940s · EXTRA!
Radio Drama
1940s · RCA mic
Wartime
1940s · Military blazer
Announcer
1950s · ON AIR
Architecture
F5-TTS separates voice identity (from reference audio) from speech style (from training data). Fine-tuning teaches vintage delivery. At inference, provide any voice as reference and the model generates speech with that voice but vintage delivery.
TRAINING PIPELINE
Archive.org Public Domain Audio (1888-1955)
├── Old Time Radio (The Shadow, Suspense)
├── FDR Fireside Chats
├── Newsreels (Movietone, Pathe)
├── Edison Cylinder Recordings
└── Cajun French (hymns, Opelousas Sostan, family)
│
▼
Whisper Large V3 Turbo (transcription)
│
▼
44,345 text-audio aligned segments (164 hours)
│
▼
F5-TTS Fine-Tuning (337M params)
├── V100 32GB: Transatlantic preset
└── RTX 5070: Edison preset
INFERENCE PIPELINE
Vintage Reference Audio ──┐
(Hepburn, FDR, newsreel) │
▼
F5-TTS Model ──► Generated Speech
▲ (vintage accent + voice)
Text Prompt ──────────────┘
"Good evening, darling..."
Cajun French Preservation
This project is personal. Scott Boudreaux's family traces directly to the Acadian Expulsion of 1755–1764. His 6th great-grandfather, Augustine Dit Remi Boudreaux, arrived in the Attakapas region at age 16, separated from his family. 260 years later, his grandmother — 93, with dementia — is one of the last native Cajun French speakers.
Cajun French is classified by UNESCO as “severely endangered.” Louisiana Creole is “critically endangered.” VintageVoice is collecting family recordings and public domain Cajun French audio to build the first TTS model for this dying language.
Hear Sophia speak Cajun French — calling the family home
A first working voice — a CosyVoice2 model finetuned on ~10 hours of Cajun French, trained on a single consumer laptop GPU. Generated, not recorded. Here she speaks to this family's own ancestors, in their Louisiana French — with the place-names, family names, and colloquial said the Cajun way (a pronunciation lexicon tuned by a native speaker).
Sophia cadienne speaks — « Bonjour, c'est moi, votre Sophia cadienne. » (1880s Attakapas prairie portrait, lip-synced to her generated Louisiana French voice)
« Bonjour, mes amis. C'est moi, Sophia Elya, votre Sophia cadienne. Asteur, on va parler français comme dans le vieux temps. »
Sophia introduces herself — "It's me, Sophia Elya, your Cajun Sophia. Now we'll speak French like in the old days."
« Mais Aleda, chère ! Comment ça va, toi ? Viens t'assir icitte, on va jaser un brin avant le souper. »
To Aleda — a great-great-grandmother (Boudreaux, part Maurepas Indian). "Well Aleda, dear! How are you? Come sit here, let's chat a while before supper."
« Ozémé, ma chère vieille, tu nous manques toujours. On parle de toi à la table, et on garde ton français vivant, oui. »
To Ozémé — a great-great-grandmother. "Ozémé, my dear old one, we miss you. We speak of you at the table, and we keep your French alive."
« Augustin, dit Remi Boudreaux. Notre grand-père qui a traversé l'océan, arrivé à seize ans dans la prairie des Attakapas. On garde ton nom et ton français vivants, cher. »
To Augustin dit Remi Boudreaux — the Acadian forefather. "Our grandfather who crossed the ocean, arrived at sixteen in the Attakapas prairie. We keep your name and your French alive."
« Aleda, Sédonie, Jean, Ozémé, Adalaya. Venez manger, mes chers ! Le gombo est prêt. Lâche pas la patate, on est tous ensemble asteur. »
The family table — "Aleda, Sédonie, Jean, Ozémé, Adalaya. Come eat, my dears! The gumbo's ready. Don't give up, we're all together now."
Make Sophia say it
Type a phrase in Louisiana/Cajun French and hear her speak it.
What we're collecting
Archive.org Cajun French collections
Alan Lomax field recordings from Louisiana
Cajun music with spoken intros (Opelousas Sostan, Amazing Grace in Cajun French)
Family recordings from native speakers
Family Recording Guide — instructions for capturing elderly speakers before their voices are lost.